

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 인프런
- EC2
- port forawrding
- ssh
- AWS
- sshtunneling
- helm-chart
- ChatGPT
- 인프런강의
- 워커노드
- kaniko
- Docker
- ingress-nginx
- ElastiCache
- elasticahe
- redis oss
- argocd
- jnlp
- k8s
- RDS
- datagrip
- Tunneling
- Kubernetes
- helm
- multibranch
- ssafy #싸피 #ssafy 12기 #싸피 12기 #ssafy 합격 #싸피 합격 #합격 후기
- Certbot
- cloud controller manager
- 쿠버네티스
- vue3
- Today
- Total
처누
[Infra] 자율 프로젝트 아키텍처 설계 본문
쿠버네티스로 "운영할 가치가 있는" 최소한의 프로젝트 볼륨
아래 조건 중 하나 이상이면 쿠버네티스는 충분히 쓸 가치가 있다.
- 서비스가 3개 이상 (ex. 프론트엔드, 백엔드, DB, 메시징 서버 분리)
- 릴리즈 주기가 빠름 (ex. 주 1회 이상 배포)
- 버전 롤백이 필요함 (ex. 장애 시 빠르게 롤백하고 싶음)
- 트래픽이 가변적임 (ex. 새벽엔 10 req/sec, 낮엔 1000 req/sec)
- 장애가 발생했을 때 자동 복구가 필요함 (ex. 노드 다운 시 Pod 재스케줄링)
- 모든 걸 코드로 관리하고 싶음 (IaC: Infrastructure as Code)
단순 서버 1~2개, 변경 거의 없음, 트래픽 일정 → 쿠버네티스 필요 없음. (EC2 + Docker Compose가 더 낫다.)
현재 가지고 있는 서버는
- m6i.large(2vCPU,8GB) 1대
- m6i.xlarge(4vCPU,16GB) 2대
- aws lightsail(4 CPU, 16GB) 1대
- ec2 free tier 1대
Kubernetes 워커 노드는 "서비스를 분산 배치"하기 위한 게 아니라, "장애 시에도 살아남을 수 있도록 복제해서 자동 복구하기 위한 용도"다. 워커 노드가 죽어도 서비스는 다른 워커에서 계속 살아 있어야 한다.
마스터는 뇌다. 일시키지 말고, 관리만 해라.
구상중인 설계는 다음과 같다. eks를 사용하지 않기 때문에 마스터 노드를 직접 구축해야한다.
- m6i.large 1대 -> 마스터 노드
- Control Plane(kube-apiserver,scheduler,controller-manager)
- etcd
- 클러스터 Add-ons설치(CoreDNS, kube-proxyx, CNI 네트워크 플러그인 설치) - calico, flannel 등/calico 설치할 예정
- 모니터링용 리소스 설치(Metrics Server 설치) - metrics-server, prometheus-operator
- Cert-Manger(certbot을 통해 tls 인증할 예정인데 그래도 필요한지? - 필요없음 certbot을 통해 수동 인증하기 때문)
- Pod Scheduling 시 taints 걸어서 워커만 워크로드 태우게 하기
kubectl taint nodes <마스터 노드명> node-role.kubernetes.io/master=:NoSchedule- Helm
- ArgoCD
- m6i.xlarge 2대 -> 워커 노드
- prod-worker-01에 작업할 내용
- Nginx Ingress Controller 설치 - LoadBalancer로 배포
- External-DNS(Route53 자동 연동)
- Helm 배포시 --set aws.credentials, --set policy=sync
- LoadBalancer 타입 + 외부 IP 연결 (AWS ELB 자동 생성)
- promtail
- prod-worker-02에 작업할 내용
- Jenkins
- promtail
- prod-worker-01에 작업할 내용
- aws lightsail 1대 -> 모니터링용
- prometheus, loki, grafana
- kafka(00,01,02), kafka ui -> docker compose로 배포
- ec2 free tier 1대 -> 컨피그 서버용
Calico를 추천하는 이유
- 성능: AWS EC2 환경에서도 빠른 Pod 간 통신 지원.
- 안정성: 수천 개 이상의 Pod 운영 경험 검증됨.
- 보안: Kubernetes NetworkPolicy(네트워크 통제) 완벽 지원.
- 운영 난이도: 기본 설정만으로도 충분히 쓸 수 있음 (설치 쉽다).
- 추후 확장성: 나중에 Node 늘리거나 MSA 쪼개도 유연하게 따라감.
- Ingress랑 호환성: NGINX Ingress Controller + Calico 조합 아주 안정적임.
- AWS 호환성: AWS ENI 네이티브 통합 가능 (선택사항)
LoadBalancer 타입으로 Ingress Controller 배포하는 흐름

고려해야 할 사항
- 마스터 노드 백업/복구
- 마스터 하나 죽으면 수동 복구
- etcd 백업 주기적으로 실행(etcdctl snapshot save)
- 워커 노드 고가용성
- PodDsiruptionBudget(PDB)와 Anti-Affinity 설정 걸기 -> 특정 워커 1대 죽어도 서비스 유지되도록
- Lightsail 모니터링 서버 네트워크 딜레이
- 워커 노드 메트릭 수집 시 1~2초 지연 감수해야함.
- 심한 지연 생기면 EC2로 전환하는 것 고려
- Storage와 로그 관리
- large,xlarge 디스크 IOPS(초당 입출력 속도)는 General Purpose SSD(gp2)면 충분
- Prometheus TSDB 데이터는 최소 100GB 이상 볼륨 잡을 것.(default 15일 retention 잡으면 금방 참.)
- Ingress Controller
- Nginx Ingress Controller 별도로 깔아서 트래픽 관리
- AWS LBC까지 붙이면 External Traffic Management 하기
- Node Grouping 고려
- 두 노드를 한 NodeGroup에 넣고 AutoScaling 설정도 여유있게 하기(min2, max4)
예상 아키텍처
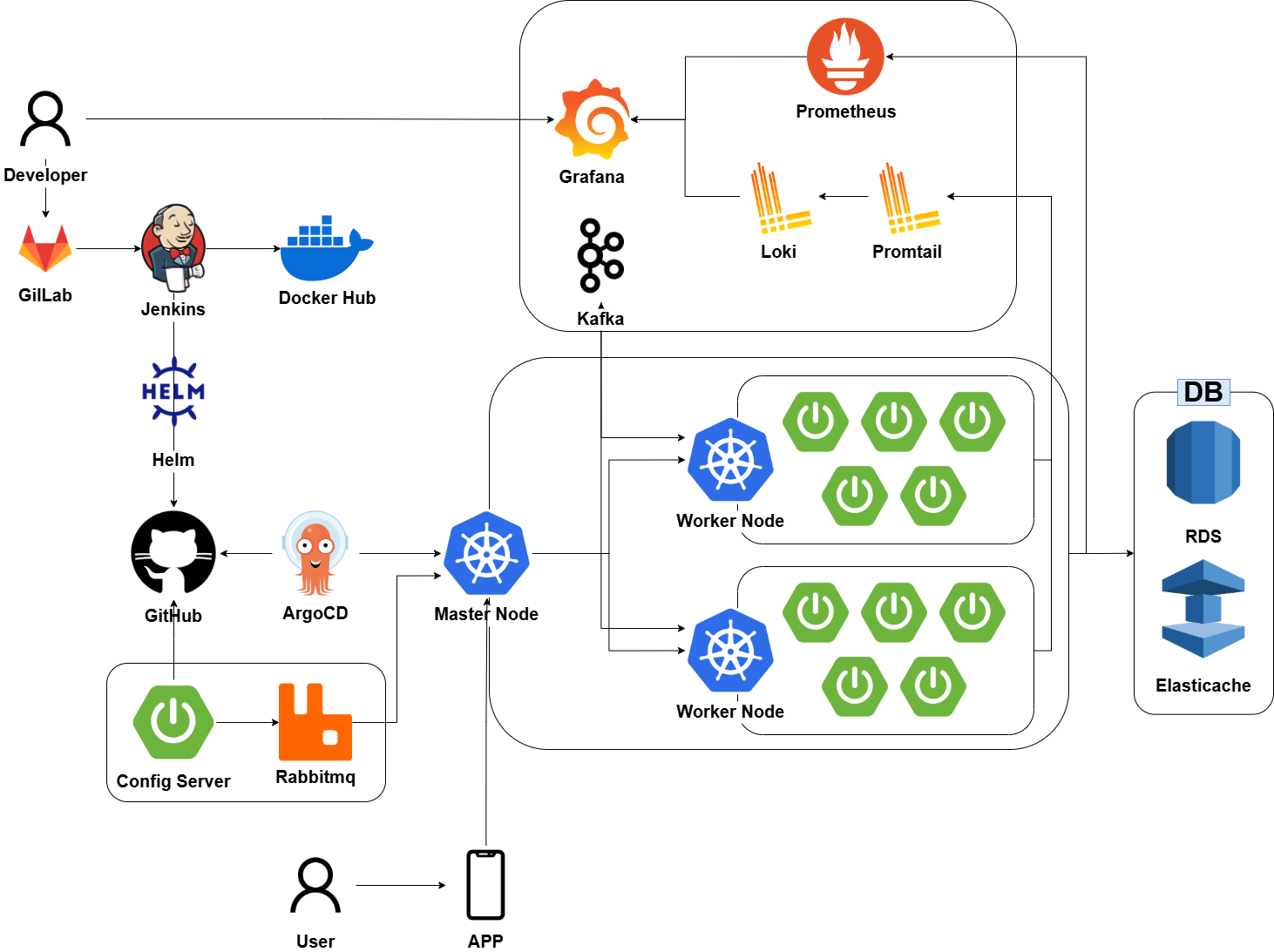
- 모니터링 + Kafka를 클러스터 안에 넣어야 할지 고민이다.
- Kafka의 화살표 방향을 저렇게 하는게 최선일까?
궁금증 ? ? ?
최근 공고를 보며 k8s + istio를 기술 스택으로 요구하는 기업을 봤다. istio를 적용할 수는 없을까?
-> 어중간하게 사용하면 복잡도만 늘고 얻는 이점은 적을 수 있다.
Istio는 Service Mesh의 대표적인 구현체다. 쉽게 말해, 마이크로서비스 간 통신을 제어, 보완, 모니터링하기 위한 네트워크 레이어다.
istio는 아래 3가지 중심으로 작동한다.
- Sidecar 프록시(Pilot + Envoy)
- 각 서비스마다 envoy proxy를 사이드카 컨테이너로 붙여서 통신을 가로채고 제어함.
- envoy는 대규모 현대 서비스 지향 아키텍처를 위해 설계된 L7 proxy 및 통신 버스임.
- Control Plane
- 중앙에서 네트워크 정책, 보안, 라우팅 규칙을 설정하고 사이드카에 전달함.
- Data Plane
- 실제 트래픽은 각 서비스 옆에 붙은 Envoy가 처리다음과 같은 경우에 Istio를 사용하는 게 적합하다고 한다.
- MSA 규모가 크고, 서비스가 많을 때
- 10~20개 이상의 마이크로서비스가 있고, 서비스 간 통신이 복잡할 때
- 트래픽 흐름을 정밀하게 제어하고 싶은 경우
- 보안이 중요한 서비스
- 서비스 간 암호화된 통신(mTLS)이 필수일 때
- 외부 접근을 철저히 통제하고 싶을 때
- 관측성(Observability)이 중요한 경우
- 트래픽 흐름, 실패율, 응답시간을 시각화하고 싶은 경우
- Jaeger/Zipkin으로 분산 추적이 필요할 때
- 운영자가 네트워크를 통제하고 싶을 때
- 운영팀이 개발자가 코드를 수정하지 않고 배포 전략을 제어하고 싶을 때반대로 Istio를 도입하지 말아야 할 경우는 다음과 같다.
- 서비스 수가 적을 때
- 마이크로 서비스가 3~5개 이하라면, 과도한 복잡도를 유발함.
- 리소스가 부족한 환경일 때
- Istio는 Envoy + Control Plane 구성으로 리소스 소모가 큼.
- 운영 경험이 부족할 때
- 학습 곡선이 높고, 디버깅이 어려워질 수 있음.
- 단순한 기능만 필요할 때
- 단순한 서비스 디스커버리나 기본 인그레스면 K8s native Ingress나 Nginx로도 충분함.
loki를 ec2 lightsail에 설치하게 되면 클러스터 외부에 설치하게 되는데 로그 수집 시 리소스에 영향이 있지 않을까?
-> 클러스터 외부에 Loki를 두면 네트워크 지연, 리소스 소비, 장애 전파 가능성이 약간 증가하지만, 운영상 감당 가능한 수준이고, 전체 아키텍처 안전성을 높이는 장점이 더 크다.
클러스터 외부에 Loki를 설치하면 다음과 같은 이점이 있다.
- 클러스터 내 장애가 생겼을 때 Loki는 살아있다. 즉, 로그는 계속 유지된다.
- 클러스터 노드 리소스를 사용하지 않고 모니터링 노드에 부하가 분산된다.
- ec2 lightsail 독립 디스크로 운영이 가능하다.
- 로그 인프라 분리가 가능하다.(보안 강화)
prometheus를 통해 클러스터의 성능을 모니터링 해야하는데 ec2 lightsail에 설치하게 되면 클러스터 외부이기 때문에 모니털링을 못하는 것이 아닌가?
-> Prometheus가 클러스터 외부에 설치되어 있다면, 기본 설정만으로는 쿠버네티스 클러스터 내부 메트릭 수집을 하지 못함. 하지만, 설정만 추가하면 외부에서도 모니터링이 가능함. 단, 클러스터 내부와 통신이 가능해야 하며, kube-state-metrics, node-exporter 같은 exporter들을 클러스터에따로 배포해야 함.
Ec2 lightsail도 클러스터 내부에 있도록 워커 노드로 설정하면 안될까?
- VPC 외부에 있음
- Lightsail은 EC2와 VPC가 분리된 별도 네트워크, ENI, VPC Peering 없이 쿠버네티스 내부 통신이 제대로 안될 수 있음.
- 불안정한 네트워크 품질
- Lightsail은 EC2보다 네트워크 QoS가 떨어지고, latency가 더 크다. Prometheus, Kafka 같은 시스템에 치명적일 수 있음.
- 리소스 제어 부족
- EC2는 EBS, ENI, 보안 그룹, IAM 등 완전한 제어가 가능하지만, Lightsail은 제한적이다. 디스크 IOPS, 네트워크 대역폭에 한계가 있음.
- Kubernetes 네트워크 플러그인과의 호환성
- Calico, Cilium 같은 CN가 VPC 내 노드 간 통신을 가정하고 동작함. Lightsail은 이와 충돌 가능성 있음.
- 정책적 혼란
- 클러스터 내에 위치한 Pod인데, 실은 VPC 외부, 정잭 통제, 보안 통제가 애매해진다.(예: NetworkPolicy, ServiceMesh 적용 불가)